
Personalized federated learning for predicting disability progression in multiple sclerosis using real-world routine clinical data
- Oct 6, 2025
- 4 min read
By: Ashkan Pirmani, Edward De Brouwer, . . . , Liesbet M. Peeters & Yves Moreau

Multiple sclerosis (MS) is a complex neurological disorder affecting millions worldwide. Predicting disability progression in MS is a key challenge for improving treatment decisions. Despite the promise of machine learning, progress is constrained by fragmented data, privacy and governance restrictions, and the inherent difficulty of pooling information across institutions. These challenges are amplified by the fact that MS is a relatively low-prevalence disease, with available datasets already dispersed across many centers. Beyond fragmentation, the data that does exist is highly heterogeneous. Centers differ in the number of patients they can serve and in the distributions of clinical outcomes they record. As shown below in Figure 1, such heterogeneity (here illustrated by country-level partitions) creates non-IID data distributions that are problematic not only for centralized aggregation but also for federated learning (FL).




Figure 1: Heterogeneity of country-specific data partitions for federated learning. (a) Log-scaled distribution of country-specific dataset sizes DCi, (b) Class imbalance across countries, showing underrepresentation of Class 1 (MS worsening confirmed) relative to Class 0.
In standard FL, as shown in Figure 2a, updates from sites with different sample sizes, patient characteristics, and recording practices can diverge, leading to client drift, conflicting gradients, and poor convergence. These limitations motivate the use of personalized federated learning (PFL), like in Figure 2b, which seeks to balance global collaboration with local adaptation to better capture the variability inherent in MS populations.



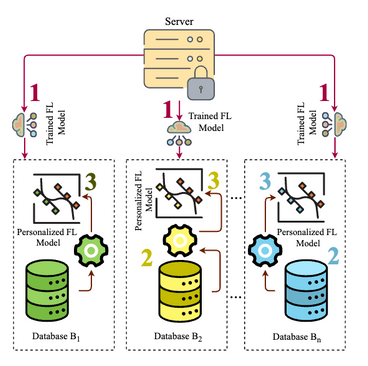
Figure 2: Baseline Federated Learning (FL) vs Personalized Federated Learning (PFL). (a) Baseline FL: Depicts the classic iterative process in which multiple clients (e.g., clinical sites) collaboratively train a single global model. Each client gets the current global model (Step 1) and trains it locally on its private dataset (Step 2). The locally updated parameters are then uploaded to a central server (Steps 3) and aggregated (Step 4), refining the global model without exchanging any raw patient data. (Step 5) Dissemination of the updated global model to all clients for continued local training based on aggregated knowledge. (b) PFL via Fine-Tuning: Shows how a pre-trained global FL model (Step 1) is shared with each client. Each client fine-tunes this model on its local dataset (Step 2), creating a personalized version (Step 3) that reflects client-specific characteristics. This approach retains the benefits of cross-site collaboration while allowing for tailored predictions.
We evaluated and compared five modeling paradigms: pooled centralized training, baseline FL, two PFL approaches, and local-only modeling. Among personalization methods, we developed AdaptiveDualBranchNet, which splits the model into a shared core trained across collaborators and local extension layers tailored to each site, which the architecture of this model in Figure 3. We also tested a fine-tuning strategy, where the global FL model is adapted further on local data.

Figure 3: The diagram depicts the structure of AdaptiveDualBranchNet models. The Adap- tiveDualBranchNet architecture extends the baseline multi-layer perceptron by introducing a dual-branch structure comprising Core Layers and Extension Layers. The Core Layers, highlighted in yellow, retain the fully connected structure of the Baseline’s Hidden Layers and are shared across all clients, being trained in an FL setup to capture fundamental and generalizable features from the data. In contrast, the Extension Layers, shown in orange, are client-specific and designed to learn personalized representations. These layers receive input from the same Input Layer as the Core Layers but follow a distinct structural design tailored to capture additional, domain or client-specific variations in the data. Unlike the Core Layers, which are updated through FL aggregation, the Extension Layers remain locally trained, enabling each client to adapt the model to its unique distribution while benefiting from the shared knowledge encoded in the Core Layers. At the final stage, both branches feed into a set of processing nodes (depicted as c -units in red), which consolidate the learned representations before reaching the Output Layer Y . This separation between federated (global) and local (personalized) training allows the AdaptiveDualBranchNet to balance generalization and personalization, making it particularly effective in heterogeneous data environments where both shared knowledge and client-specific adaptations are neces- sary.
For this study, we used routine clinical data from one of the largest MS cohorts to date, comprising more than 26,000 patients across multiple centers. On this large and heterogeneous dataset, as shown in Table 1, PFL methods consistently outperformed baseline FL approaches. In particular, personalized FedProx (ROC-AUC 0.8398 ± 0.0019) and personalized FedAVG (ROC-AUC 0.8384 ± 0.0014) achieved significantly better performance than their non-personalized counterparts. Table 1: Performance Metrics (ROC–AUC and AUC–PR) for Personalized Federated Learn- ing Models Compared to Federated Learning Baseline Across Various Strategies. Note: ‘Centralized’ results are included for comparison purposes and do not fall under the FL or PFL categories. For brevity, the term “AdaptiveDualBranchNet” will be referred to simply as “Adaptive” throughout this manuscript. Additionally, the non-personalized FL model is commonly referred to as the baseline FL paradigm. The value after ‘±’ denotes the standard deviation of the measurements

These results make clear that personalization is essential for building accurate, privacy-aware predictive models in heterogeneous clinical settings. PFL thus brings us closer to reliable early prediction of disability progression in MS.
The critical role of VSC infrastructure.
From a computational standpoint, FL requires frequent communication between the central server and participating clients, synchronized parameter updates across sites, and coordination among clients with heterogeneous dataset sizes and computational capabilities. Executing these processes at scale introduces substantial system overhead, increases communication latency, and demands significant computational resources for both server orchestration and client participation. The Flemish Supercomputer Center (VSC) made these experiments feasible. VSC’s high-performance infrastructure, combined with Flower for federated orchestration and Ray for distributed execution, enabled us to efficiently manage client-server workflows, parallelize training, and conduct PFL at scale. This technical support made it possible to evaluate architectures like AdaptiveDualBranchNet on data from one of the largest MS cohorts available.
Read the full publication in NPJ here

🔍 Your Research Matters — Let’s Share It!
Have you used VSC’s computing power in your research? Did our infrastructure support your simulations, data analysis, or workflow?
We’d love to hear about it!
Take part in our #ShareYourSuccess campaign and show how VSC helped move your research forward. Whether it’s a publication, a project highlight, or a visual from your work, your story can inspire others.
🖥️ Be featured on our website and social media. Show the impact of your work. Help grow our research community
📬 Submit your story: https://www.vscentrum.be/sys


